Go Web Programming: [03/01] Web Working Principles
Web working Principles
일반적으로 웹페이지를 방문할 경우 웹 브라우저를 열고 해당 주소를 입력한 후 엔터키를 누르면,
당신이 보고 싶은 콘텐츠가 브라우저 화면에 표시 됩니다.
이러한 단순한 작업의 이면에는 실제적으로 어떤 과정을 거치는 것인지를 알아보도록 하겠습니다.
대부분의 경우, 네트워크 프로그램을 사용할 경우에는 실제 다음과 같이 작동하게 됩니다.
먼저, 웹브라우저 자체는 클라이언트에 해당 합니다.(google.com 의 예로 설명합니다.)
- 웹브라우저를 열고 해당
URL주소를 입력하면, - 웹브라우저는
DNS서버에게 해당 URL을 제공하는 시스템의IP주소를 가르켜 주게 됩니다. - 그후, 웹브라이저는
TCP연결을 수립하게 됩니다. - TCP연결이 된 후
HTTP Request요청패킷을 전송하고, 웹 서버는 요청패킷을 처리 합니다. - 웹 서버는 자신이 서비스하는 루틴을 호출하고,
HTTP Response응답패킷을 반환 합니다. - 웹 브라우저가 서버로 부터 받은 응답패킷의 바디부분을 읽어서 표시한 후
TCP연결을 종료 합니다.
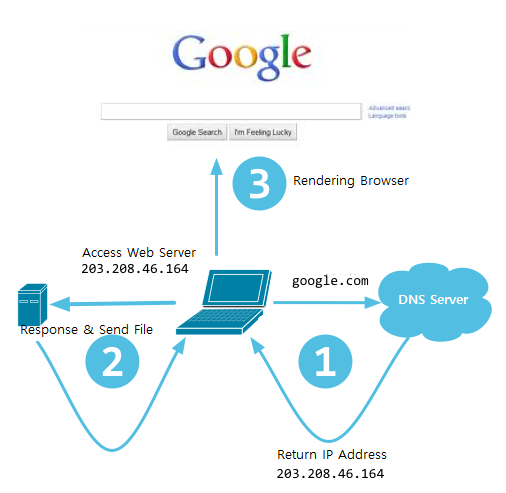
그림 3.1 사용자가 Web 서버에 액세스하는 과정
Web 서버는 HTTP 서버 라고도 합니다. HTTP 프로토콜을 통해서 클라이언트와 통신 합니다. 여기서 클라이언트는
일반적으로 Web 브라우저를 의미 합니다.(사실 모바일 환경에서도 내부적으로 브라우저로 실행되고 있습니다.)
Web 서버의 작동 원리는 쉽게 설명 할 수 있습니다.
- 클라이언트가 TCP/IP 프로토콜을 통해 서버까지 TCP 연결을 설정 합니다.
- 클라이언트는 서버에게 HTTP 요청 패킷을 전송하고 해당 서버의 자원 문서를 요청 합니다.
- 서버는 클라이언트에게 HTTP 응답 패킷을 전송하고, 만약 요구 된 자원에 동적콘텐츠가 포함된 경우,
서버의 동적언어 인터프리터 엔진을 통해 “동적 내용” 처리 루틴을 호출해서 처리 합니다.
동적 콘텐츠를 처리한 후 얻어진 데이터를 클라이언트에 반환 합니다. - 클라이언트와 서버의 접속이 해제 됩니다.
- 클라이언트는 HTML 문서를 해석한 후 화면에 도형이나 그림 또는 문자로 해당 결과를 표시 합니다.
HTTP 작업이 단순하게 처리됨을 알 수 있습니다. 겉으로는 복잡하게 처리되는듯 보이지만 원리는 매우 간단 합니다.
조심할 점은 클라이언트와 서버가 항상 연결되어있는 것이 아닌 점입니다. 서버가 응답패킷을 보낸 후 클라이언트와
곧바로 연결을 끊고 다음 요청을 처리하기 위해 다시 대기상태에 들어가기 때문입니다.
URL과 DNS 확인
홈페이지에 대한 접금은 항상 URL을 통해서만 이뤄집니다. 그렇다면 URL이란 도대체 무엇일까요?
URL(Uniform Resource Locator)은 “단일 자원 위치 지정자” 입니다.
즉, 네트워크 리소스를 표현하고 있습니다. 기본적인 구문은 다음과 같습니다.
scheme://host[:port#]/path/.../[?query-string][#anchor]
- scheme
로레벨 프로토콜을 지정 합니다. (예: http, https, ftp...)
- host
HTTP 서버의 IP 주소 또는 도메인
- port
HTTP 서버의 기본 포트 번호는 `80` 입니다. 이 경우 포트 번호는 생략 할 수 있습니다.
만약 다른 포트를 사용하는 경우 해당 포트를 지정해야 합니다. 예를들어 `http://www.naver.com:8080/`
- path
해당 자원의 경로
- query-string
HTTP 서버로 보내는 데이터
- anchor 앵커
DNS(Domain Name System)는 “도메인 이름 시스템”의 약자 입니다.
이것은 인터넷 조직의 트리 구조와 네트워크 서비스에대한 이름 풀이 시스템 입니다. 이러한 DNS서비스는 TCP/IP 기반으로
작동됩니다. 호스트 이름 또는 도메인을 실제로 서비스하는 IP 주소로 변환하는 작업을 수행하고 있습니다.
DNS는 이러한 일을 처리하는 번역기와 같은 개념 입니다.
이 기본적인 작동 원리는 아래 그림에 나와있는대로 입니다.
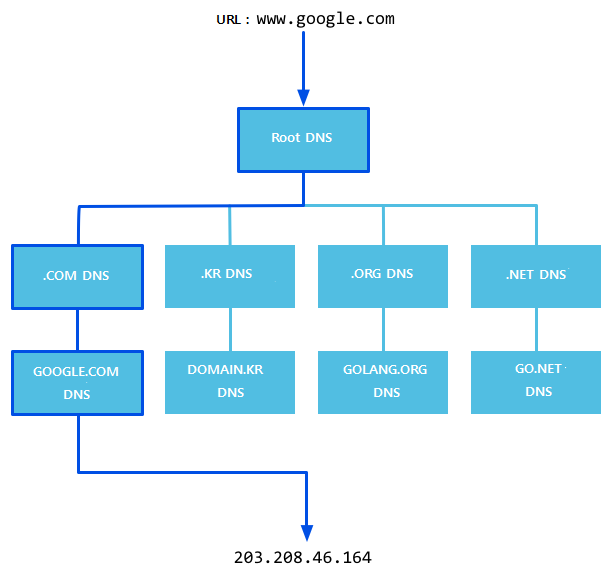
그림 3.2 DNS의 동작 원리
DNS 이름풀이 시스템의 자세한 처리는 다음과 같습니다. 이 과정은 DNS 처리방식을 이해하는데 도움이 됩니다.
브라우저에서 www.qq.com 도메인주소(URL)를 입력합니다.
운영체제는 먼저로컬 hosts 파일에 해당 주소가 있는지 먼저 검사 합니다. 만약 존재한다면,이 IP 주소를 사용
합니다. 이것으로 도메인 이름풀이 과정은 별도의 추가 과정없이 종료 됩니다.만약 로컬
hosts 파일에 해당 도메인값이 없다면, 로컬 DNS 버퍼에서 찾습니다.
만약 있으면 이를 반환한 후 종료 됩니다.만약 hosts, 로컬 DNS 버퍼 어디에도 해당 도메인이 없는 경우는 먼저 TCP/IP 옵션에 설정된
기본 DNS 서버를 찾습니다. 이것을로컬 DNS 서버라고 합니다. 이 서버가 이름풀이 요청을 받을때, 만약 도메인 이름이 로컬에 포함되어
있는 경우, 해당 결과를 클라이언트에 반환한 후 이름풀이 과정을 종료 합니다.만약 도메인 이름이 로컬 DNS 서버에도 없고, 해당 URL을 버퍼링하고 있다면 이 IP 주소를 반환후 종료 합니다.
만약 로컬 DNS 서버의 영역 파일과 버퍼링에도 존재하지 않는 경우의 처리방식은 로컬 DNS 서버의 설정에 따라
(리피터가 설정되어 있는지) 검사방법 결정을 시도 합니다.
만약 전송 모드가 사용되지 않았다면 로컬 DNS는 해당 요청을루트 DNS 서버에 보냅니다.
루트 DNS 서버는 요청을 받은 후, 도메인 이름(.com)이 누구에 의해서 권한을받고 관리되고 있는지를 판단한 후,
해당 처리 서버의 IP 주소를 반환 합니다. 그 후, 로컬 DNS 서버가 IP 정보를 받은 후다시,.com 도메인을 담당하는
서버와 연결 합니다. .com 도메인을 담당하는 서버가 요청을 받은 후, 만일 자체에서 이름풀이를 처리하지 못하면,
.com 도메인을 관리하는 하부 레이어의 DNS 서버 주소(qq.com)를 로컬 DNS 서버에 보냅니다.
로컬 DNS 서버가 qq.com 도메인을 서비스하는 서버를 찾은 후 www.qq.com 호스트를 찾을 때까지의 이 동작을 반복 합니다.만약 전송 모드를 사용하는 경우에는 DNS 서버는 이름풀이 요청을 하나의 DNS 서버로 전송 합니다.
이 서버가 이름풀이 과정을 처리하지 못할 경우 루트 DNS를 찾아내는 상기의 방법대로 처리 합니다
이처럼 상당히 복잡한 내부 과정을 운영체제에서 처리하고 있습니다.
요약하면, 브라우저에서 마지막으로 요청을 보낸 후, 실제로는 IP 주소를 기반으로 해당 서버와 정보 교환을 하고 있는것 입니다.
HTTP 프로토콜 상세
HTTP 프로토콜은 Web 작업의 핵심 입니다. 따라서 Web의 작업 방법을 이해하기 위해서는 HTTP 프로토콜이 어떤 작업을 처리하는
지에 대한것을 이해할 필요가 있습니다.
HTTP는 Web 서버에서 브라우저(클라이언트)와 Internet을 통해 데이터를 교환하는 프로토콜입니다.
TCP 프로토콜에 기반하기 때문에, 일반적으로 TCP 80번 포트가 주로 사용 됩니다. 요청 및 응답 프로토콜을 기반으로 합니다.
클라이언트가 요청을 보내면 서버에서 해당 요청에 대해서 응답 합니다.
HTTP는 클라이언트가 항상 연결요청을 요구해도 서버는 주도적으로 클라이언트와 연결 할 수 없습니다. 단지 요청에 대해서 응답할 뿐입니다.
또한 클라이언트에 콜백 연결을 보낼 수도 없습니다. 클라이언트와 서버는 통신 중간에 연결을 중단 할 수 있습니다.
예를 들어, 브라우저에서 파일을 다운로드 할 때 “정지”버튼을 클릭하여 파일의 다운로드를 중단하고 서버와의 HTTP 연결을 닫을 수 있습니다.
HTTP 프로토콜은 상태 정보를 사용하지 않습니다. 동일한 클라이언트가 했던 과거 요청과 또다른 요청간의 아무런 상관 관계도 없습니다.
HTTP 서버측에서는 이 두 요청이 동일한 클라이언트에서 발생 된 것인지조차 알지 못합니다. 이러한 상태 지속 문제를 해결하기 위해서,
Web 프로그램에서는 Cookie와 같은 도구를 도입하여 연결 지속 가능한 상태를 유지하고 있습니다.
HTTP 프로토콜은 TCP 프로토콜로 구축되기 때문에, TCP 공격은 HTTP 통신에 동일한 수준으로 영향을 미칩니다.
예를 들어, 일명 볼공격으로(SYN Flood) 현재까지 가장 유행했던 DoS(서비스 거부 공격)와 DdoS(분산 서비스 거부 공격) 등이 있습니다.
이것은 TCP 프로토콜의 구조적인 결함을 이용해서 대량으로 위조된 TCP 연결 요청을 보내는 공격 방법입니다.
이로 인해 공격 받은 서버의 자원이 고갈(CPU 부하와 메모리 부족)되도록 하는 공격 입니다.
HTTP 요청 패킷 (브라우저 정보)
우선 Request 패킷의 구조를 살펴보기로 하겠습니다. Request 패킷은 세 부분으로 구성됩니다.
첫 번째 부분은 Request line(요청행)이고, 두 번째 부분은 Request header(요청헤더)이며, 세 번째 부분은 body(바디)로
구성되어 있습니다. header와 body 사이에는 빈 줄로 구분하며, 요청 패킷의 예는 다음과 같습니다.
GET /domains/example/ HTTP/1.1 // 요청 행 : 요청 방법 요청URI HTTP 프로토콜 / 프로토콜 버전
Host:www.iana.org // 서버의 호스트 이름
User-Agent:Mozilla/5.0(Windows NT 6.1) AppleWebKit/537.4(KHTML,likeGecko)
Chrome/22.0.1229.94 Safari/537.4 // 브라우저 정보
Accept:text/html application/xhtml + xml, application/xml; q=0.9 * / *; q = 0.8 // 클라이언트가받을 mime 타입
Accept-Encoding: gzip, deflate, sdch // 스트림 압축 지원 여부
Accept-Charset: UTF-8, *; q = 0.5 // 클라이언트 문자 집합
// 빈 줄이 요청 헤더와 바디를 분리하기 위하여 사용 됩니다.
// 바디 리소스에 대한 요청의 옵션
HTTP 프로토콜에는 서버에서 요청을 보내는 방법에 대해서 정의되어져 있습니다. 기본적으로,GET, POST, PUT, DELETE 4가지 입니다.
URL 주소는 한개의 네트워크 자원을 설명하고 있습니다. 또한 HTTP 프로토콜 중에서 GET, POST, PUT, DELETE이 자원의
검색, 수정, 증가, 감소 4 가지의 조작 처리에 대응하고 있습니다. 전형적인 예로서 GET, POST가 있습니다. GET은 일반적으로 자원의 정보를
취득 및 검색하는 데 사용되며, POST는 자원 정보를 업데이트하는 데 사용 됩니다.
fiddler 패킷 캡처 프로그램을 통해서 다음과 같은 요청 정보를 볼 수 있습니다.
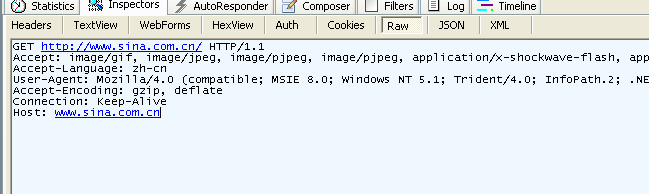
그림 3.4 fiddler에서 캡처한 GET 정보
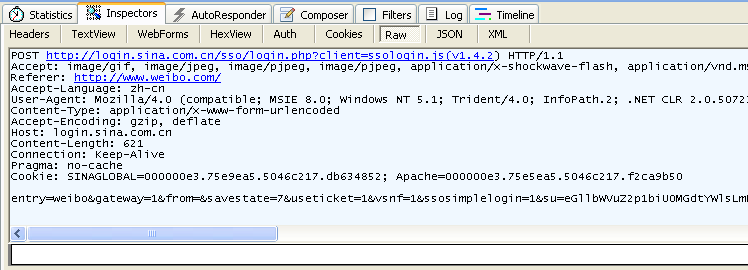
그림 3.5 fiddler에서 캡처한 POST 정보
그렇다면 GET과 POST 방식의 차이점을 살펴 보겠습니다.
- GET 요청에는 바디가 없다는 것을 알 수 있습니다. POST 요청에는 바디가 존재합니다.
- GET방식의 요청에서는 사용자가 입력하는 데이터는 URL의 끝부분에 추가되어 보내집니다.
?를 구분자로 사용해서URL과전달할 데이터를 분리해서 처리합니다. 옵션 정보들은&로
연결 합니다. 예를 들어,EditPosts.aspx?name=test1&id=12345같이 전달됩니다.
POST 메서드는 입력 데이터를 HTTP 패킷의 Body에 추가합니다. - GET 요청 처리 방식에서 사용자가 입력하는 데이터의 크기에는 제한이 있습니다.
브라우저의 URL에 입력할 수 있는 길이에 제한이 있기 때문입니다. 이에비해 POST 메서드에서 입력하는 데이터는 제한이 없습니다. - GET 메소드를 통해서 입력 된 데이터는 보안 문제를 일으 킵니다.
예를 들어, 로그인 화면이 있고 GET 메서드에서 데이터를 입력하면 사용자 이름과 암호는 URL에 나타나게 됩니다.
이때, 만약 페이지가 버퍼링되어 있거나 해커가 이 컴퓨터에 접근 할 수 있다면, 히스토리 로그에서 사용자 계정과 암호를 얻을 수 있습니다.
HTTP 응답 패킷 (서버 정보)
HTTP의 response 패킷을 살펴 보겠습니다. 구조는 다음과 같습니다.
HTTP / 1.1 200 OK // 상태 코드 표시 줄
Server: nginx / 1.0.8 // 서버가 사용하는 WEB 소프트웨어의 이름과 버전
Date: Date : Tue, 30 Oct 2016 04:14:25 KST // 전송 시간
Content-Type: text/html // 서버가 전송하는 데이터의 유형
Transfer-Encoding: chunked // 전송하는 HTTP 패킷이 분해되는 것을 나타냅니다.
Connection: keep-alive // 연결 상태 유지
Content-Length : 90 // 바디 내용의 길이
// 빈 행 헤더와 바디를 분리하기 위하여 사용 됩니다.
<! DOCTYPE html PUBLIC "- // W3C // DTD XHTML 1.0 Transitional // EN"... // 바디본문
응답 패킷의 첫 번째 줄은 상태 코드 표시줄로서 HTTP 프로토콜 버전 번호, 상태 코드 및 상태 메시지의 세 부분으로 구성되어 있습니다.
상태 코드는 HTTP 클라이언트로 HTTP 서버가 Response를 어떻게 생성하는지에 대해서 알려줍니다.
HTTP / 1.1 프로토콜 규약에서는 5종류의 상태코드가 정의되어 있습니다. 상태 코드는 3자리 숫자로 표시 됩니다.
처음 숫자는 응답의 형태를 정의하고 있습니다.
- 1XX 정보 표시 - 요청에 성공 했습니다. 계속해서 처리 합니다.
- 2XX 성공 - 요청에 성공 했습니다.
- 3XX 리디렉션 - 요청을 완료시키기 위해 전달 처리가 필요 합니다.
- 4XX 클라이언트 오류 - 요청 구문에 오류 및 요청처리를 수행 할 수 없습니다.
- 5XX 서버 오류 - 서버에서 정상적으로 요청을 수행 할 수 없습니다.
아래의 그림에서 특정한 응답 정보를 제공하고 있습니다. 왼쪽에서 자원의 응답 코드를 볼 수 있습니다.
예를 들어 200은 일반적으로 정상 처리를 의미 합니다. 302 리디렉션을 의미 합니다.
response header에 대한 상세한 정보가 표시되고 있습니다.
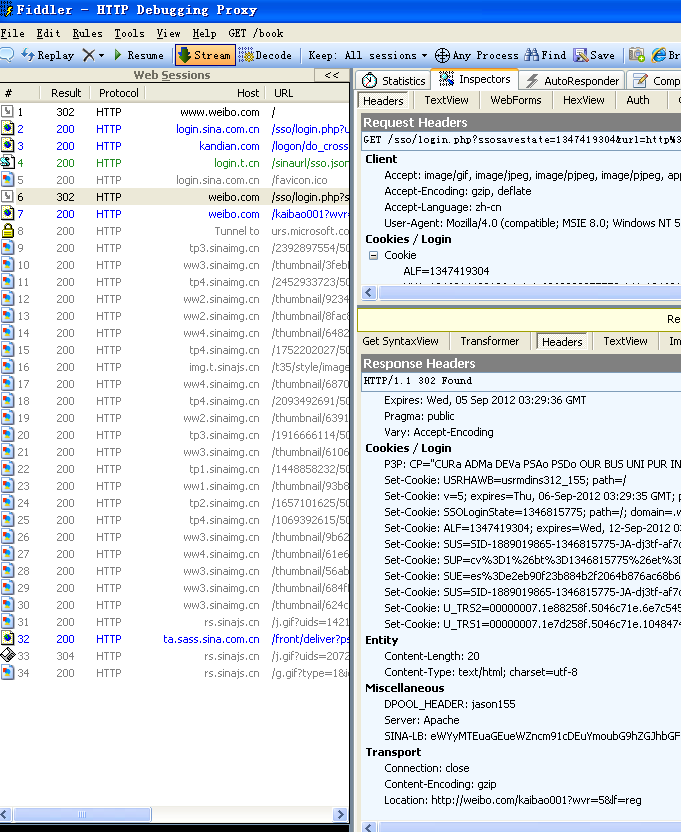
그림 3.6 홈페이지에 처음 방문할 경우 요청 정보
HTTP 프로토콜 비연결 상태 처리: keep-alive
비연결 상태 처리는 프로토콜에서 작업 처리에 대한 과거 이력 및 유지 처리를 하지 않다는 것을 의미 합니다.
서버는 클라이언트가 어떤 상태에 있는지 모릅니다. 현재 서버의 홈페이지를 접근했던 것과 어제 서버의 홈페이지를 열었던 행위
사이에는 아무런 관계도 없다는 것을 의미하고 있습니다.
HTTP는 이렇듯 비연결 상태처리 지향 프로토콜 입니다. 무상태와 HTTP프로토콜에서 TCP 연결을 유지하지 않는 것을 의미하는 것은 아닙니다.
또한, HTTP 프로토콜이 UDP 프로토콜을 사용하고 있다는 것을 의미하는 것도 아닙니다. (연결 손실에 대해)
HTTP / 1.1에서 기본적으로 Keep-Alive가 켜져 있다면 연결이 유지됩니다.
간단히 말하면, 어떤 홈페이지를 열고나면 클라이언트와 서버사이에 HTTP 데이터를 전송하기 위한 TCP 연결은 닫히지 않습니다.
만약 클라이언트가 다시금 이 서버의 홈페이지를 요청한다면 , 이미 연결되었던 TCP 연결을 계속 사용하는 방식입니다.
Keep-Alive방식은 연결을 영원히 유지하는 것이 아닙니다. 연결을 유지하는 시간이 설정 되어 있습니다.
이러한 연결유지 시간은 서버 소프트웨어(예:Apache)에서 연결유지 시간을 설정할 수 있도록 되어 있습니다.
요청 처리 방식
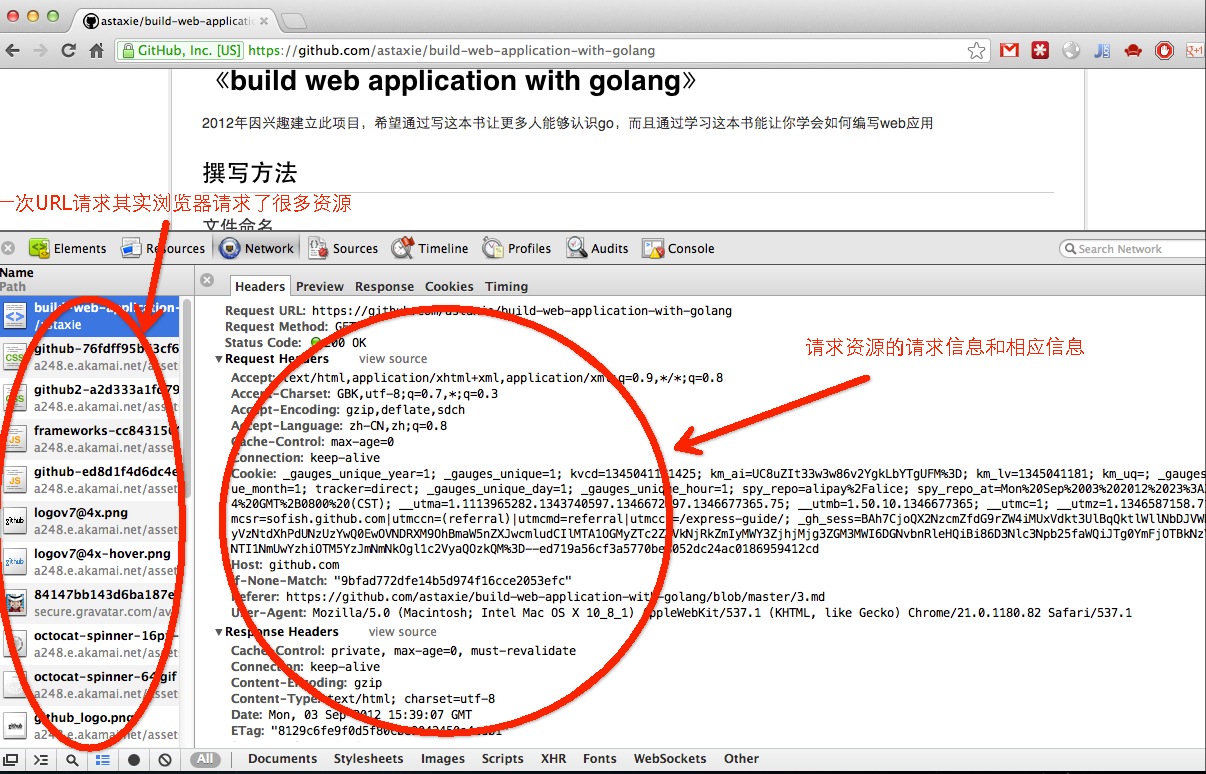
그림 3.7 request 및 response
위의 그림을 통해서 전체 통신 과정을 이해하실 거라고 생각 합니다. 동시에 하나의 URL 요청임에도 불구하고 왼쪽 창에서 표시되듯이
수 많은 자원 요청이 발생합니다. (이들은 모두 정적 파일 입니다. go언어는 정적 파일에 대해서 전문적으로 처리하는 방법을 제공합니다.)
이것은 브라우저 기능 중 하나 입니다. URL을 한 번 요청하면 서버는 html 페이지를 반환 합니다.
브라우저는 HTML을 읽고 HTML의 DOM 안에있는 이미지 링크, css 스크립트와 js 스크립트 링크를 발견 하면, 자동으로 정적 리소스의
HTTP 요청을 합니다. 정적 리소스를 검색하면 브라우저는 읽기 시작 합니다. 마지막으로 모든 자원을 정리하고 화면에 포시 합니다.
홈페이지의 개선방법으로 HTTP 요청 횟수를 줄일 수 있습니다. 즉, 가능하다면, css와 js 리소스를 같은 곳에 모으는 것입니다.
이 방법으로 홈페이지의 정적 리소스 요청 횟수를 최소한으로 줄일 수 있습니다. 홈페이지의 표시 속도를 높임과 동시에
서버의 버퍼링을 줄일 수 있습니다.